MLCommons 正式发布 Croissant 1.1,这是社区共建的机器学习数据集元数据格式最新演进版。Croissant 1.0 已确立标准化机器可读数据集元数据结构,而 1.1 版进一步引入机器可操作来源追踪、词汇互操作性以链接领域本体、结构化使用政策实现自动化许可执行,以及复杂多维数据集的增强建模。
这些新功能专为 AI “代理时代”(agentic era)量身打造,包括机器可操作来源追踪、扩展 schema 类型以及治理标签,使数据集完全可被自治系统解读和复用。
机器可操作来源追踪:完整数据血统
1.1 版新增链式保管(chain-of-custody)检查与审计功能,适用于数据中心 AI 系统。它采用 W3C PROV-O 模型记录数据集、文件或单个记录的来源,通过链接源数据和处理步骤,并归属责任代理(人员或软件)。
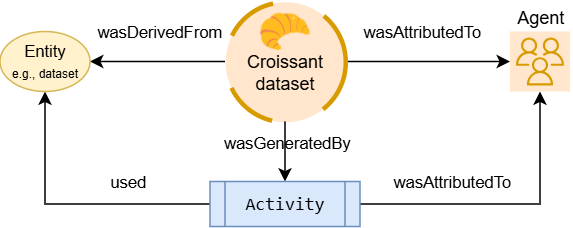
图:Croissant 捕获机器可读数据来源追踪
链式保管 方法为系统和审计者提供透明度,可追溯数据集经实体、活动和代理的完整路径,评估起源与处理历史。这嵌入元数据中的详细审计轨迹,帮助验证数据质量与合规性。例如,广泛使用的 Common Crawl 数据集已采用 Croissant 1.1 元数据,展示大规模嵌入机器可读来源与处理语义。
灵活词汇框架:提升互操作性
Croissant 1.1 引入灵活词汇框架,支持在多个层面(数据集、字段或数据类型)链接外部词汇或标识符,实现领域语义复用而无需重复发明。例如:
- 数据集层面: 可引用 Wikidata 或本体 ID(如疾病或事件)分类内容,支持跨仓库发现。
- 字段层面: 列可指向受控词汇术语(如环境或表型概念),澄清含义或引用来源。
- 数据层面: 字段值可标注语义类(如将“位置”字段链接地理概念)。
这些约定允许 Croissant 元数据直接融入现有标准。其模块化可扩展设计意味着,若数据已遵循本体,只需简单引用即可。这种互操作性对可移植性和兼容至关重要。
强化数据治理:自动化许可执行
1.1 版加强数据治理支持,使用标准政策词汇编码使用许可与限制。对于详细同意要求,集成 Data Use Ontology (DUO),允许标记许可使用类别,如“General Research Use”或“Non-Commercial Use”。这些 DUO 标签使同意限制机器可发现。
为实现更精细控制,可嵌入 W3C ODRL (Open Digital Rights Language) 政策,表达使用规则。DUO 代码或 ODRL 术语的嵌入,让代理自动验证拟议使用是否允许。这些功能使 Croissant 成为自动化工作流中的活跃数据治理执行者。
复杂数据集描述优化
Croissant 1.1 改进复杂 ML 数据集描述。字段现可表示多维数组,新属性支持语义类型、示例值或验证规则。每行数据可携带明确语义含义,如一字段为图像,另一为数值标签。
凭借这些能力,Croissant 1.1 成为当下 AI 生态的 ML 数据集元数据标准。它融合 schema.org 的广泛覆盖与可扩展词汇,生成完全机器可操作的元数据图谱,一体化捕获来源、语义与治理。
随着 AI 系统转向开放模型与自治代理,自描述元数据嵌入来源与治理变得关键。每数据集自带审计轨迹与使用政策,支持信任构建。社区采用强劲:现 70 万数据集携 Croissant 元数据,主要工具与框架(如用于机器学习的 TensorFlow 和 PyTorch,数据发布平台的 Dataverse 和 CKAN)已原生加载。主要仓库如 Hugging Face、Kaggle 和 OpenML 嵌入 Croissant 元数据。数据公司如 HumanSignal 和 CommonCrawl 的服务生成数据集集合也正兴起类似来源标准兴趣。
我们鼓励数据集创建者采用 Croissant 1.1,使数据更易发现与使用。丰富互操作元数据嵌入每数据集,有助于构建 AI 生态,让代理自治发现并使用数据,同时完全尊重来源、隐私与许可。